Addd Lucid introduction blog post
This commit is contained in:
parent
a9b4456063
commit
0f54d8c2b6
|
|
@ -0,0 +1,78 @@
|
|||
---
|
||||
layout: post
|
||||
title: "Introducing Lucid: A Swift Library For Building Robust Data Flows"
|
||||
author: trupin
|
||||
tags:
|
||||
- swift
|
||||
- architecture
|
||||
- codegen
|
||||
- featured
|
||||
team: iOS Engineering
|
||||
---
|
||||
|
||||
Lucid is a Swift library which provides a series of convenient tools for building robust data layers for applications.
|
||||
|
||||
We built it at Scribd with three main ideas in mind:
|
||||
|
||||
- **Declarative**: Lucid makes it easy to declare complex data models and provides the tools to use it with plain Swift code.
|
||||
- **Modularity**: Use the technologies which suits your data flow the best. Lucid gives you the infrastructure to seamlessly integrate the stack you want to use.
|
||||
- **Adaptability**: Built to fit most kinds of standard and non-standard server APIs, Lucid abstracts away server-side structural decisions by providing a universal client-side API.
|
||||
|
||||
Today we're happy to open source Lucid so that developers around the world can use it in their own applications.
|
||||
|
||||
### Why Lucid?
|
||||
|
||||
At Scribd, the iOS application has always been a huge part of our business. As we kept adding new features to it, the codebase became more and more complex to maintain. One of the biggest hurdles we encountered was an inconsistency in how data was handled throughout the app.
|
||||
|
||||
We decided to tackle this issue by providing a series of tools that would help us handle all of our data flows throughout the app with a single uniform API. This is how Lucid was born.
|
||||
|
||||
Our entire iOS codebase is now migrated to using Lucid for things like fetching data from the servers, storing data to disk, resolving read/write conflicts for data stored locally and remotely, listening to local data changes, etc…
|
||||
|
||||
### What features does Lucid provide?
|
||||
|
||||
The first thing to think about when working with Lucid are the data models. Lucid lets you define your data models in the form of JSON files. Those files are then interpreted by Lucid's command line tool, which generates all of the boilerplate code you'll need to handle those models in your application.
|
||||
|
||||
Once imported in your project, here's what the generated code, coupled with Lucid's framework, can help you with:
|
||||
|
||||
- Read data from your servers, local storage, or both, with a query system supported by a full featured DSL expressed in Swift.
|
||||
- Write data to your servers, or local storage, or both.
|
||||
- Listen to local data changes based on queries.
|
||||
- Standard store implementations using CoreData, in-memory caching, and disk caching.
|
||||
- Easily create and use your own stores.
|
||||
- Adaptable to most backend APIs, even those serving data in form of a tree or graph.
|
||||
- Automatic model relationship(s) fetching.
|
||||
- External plugin support for code generation.
|
||||
|
||||
### The Design
|
||||
|
||||
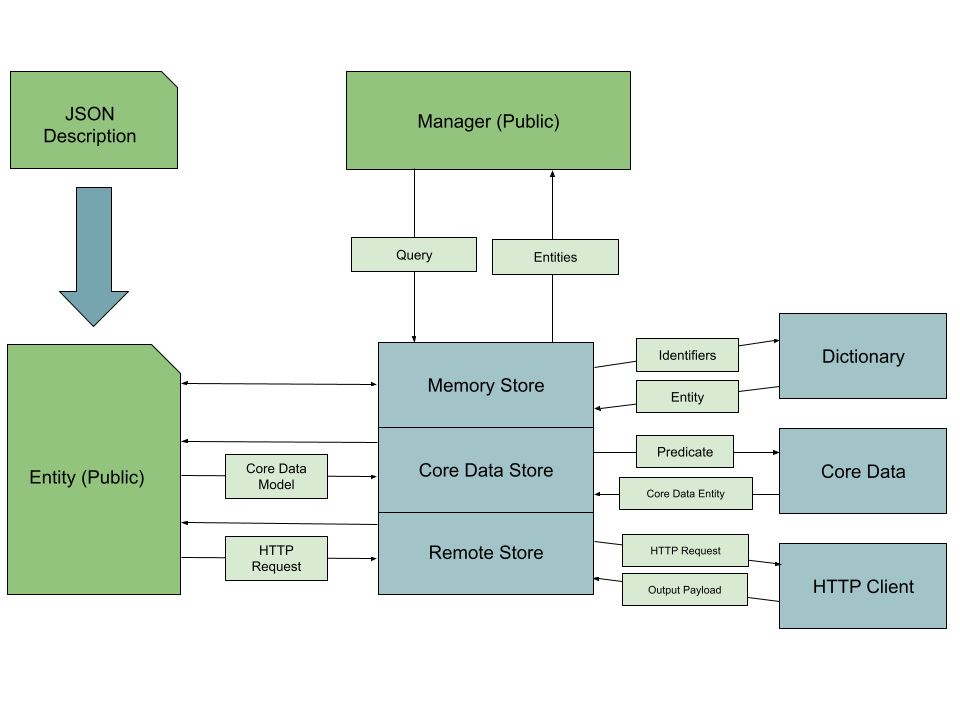
|
||||
|
||||
Lucid let you use two main types of objects:
|
||||
|
||||
- **Entity objects**, which are automatically generated from their respective JSON description files. They represent your data.
|
||||
- **Manager objects**, which provide a uniform API to read/write data to multiple locations.
|
||||
|
||||
Internally, each manager interacts with as many stores as needed. There are two types of stores:
|
||||
|
||||
- **Remote stores**. They represent the servers and directly talk to them via HTTP.
|
||||
- **Local stores**. They represent a local source of data such as a key/value cache, a Core Data database, etc...
|
||||
|
||||
In short, managers are in charge of synchronizing the data between the stores. Stores are in charge of bridging the data to specific technologies.
|
||||
|
||||
There is much more to discover about Lucid in the [documentation](https://github.com/scribd/Lucid/tree/master/Documentation/Manual).
|
||||
|
||||
### Who is Lucid for?
|
||||
|
||||
Lucid is for developers who don't want to recreate the wheel every time they need to read/write data in their application. With Lucid, you are able to declare your data models once, then chose whichever built-in functionality you need to build a robust data flow.
|
||||
|
||||
Lucid was designed to let you focus on data modeling rather than implementation details. For example, if you decide you want to store your data to disk, you just need to add a single line to your object's JSON description.
|
||||
|
||||
### Where can I find Lucid?
|
||||
|
||||
Lucid is available on [Github](https://github.com/scribd/Lucid) under the MIT license.
|
||||
|
||||
If you like Lucid, you might like other open source projects we developed at Scribd which you can find on our [Github page](https://github.com/scribd).
|
||||
|
||||
### Can I contribute?
|
||||
|
||||
You are more than welcome to contribute to Lucid. You can open a PR or file tickets on [Github](https://github.com/scribd/Lucid). Please refer to our [contributions guidelines](https://github.com/scribd/Lucid/blob/master/CONTRIBUTING.md) before doing so.
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
---
|
||||
layout: tag_page
|
||||
title: "Tag: architecture"
|
||||
tag: architecture
|
||||
robots: noindex
|
||||
---
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
---
|
||||
layout: tag_page
|
||||
title: "Tag: codegen"
|
||||
tag: codegen
|
||||
robots: noindex
|
||||
---
|
||||
Loading…
Reference in New Issue